What is Q?
Q is a serverless, general-purpose process queue specifically designed for running CGI and PHP at WebFaction.
Normally, CGI and PHP at WebFaction are great, except for one problem: there is no limit to the number of CGI workers that can get created. So during a traffic spike, it is easy to exceed your account's RAM limits, resulting in all your processes getting killed. FastCGI is often recommended as an alternative because it allows you to specify the number of worker processes that should be created. Unfortunately, due to some strange design decisions of Apache's FastCGI queue algorithm, a site can easily become unresponsive if it receives requests for long-running handlers. As a result, neither the CGI mode, nor the FastCGI mode is really acceptable for sites that need very high reliability.
Q fixes this problem by only allowing a defined number of CGI workers to run concurrently. Any additional requests that come in get queued and execute in FIFO order. This enables you to easily control the maximum amount of RAM you use during traffic spikes. This solution makes CGI a viable option again.
As a CGI-wrapper, Q has the ability to throttle requests based on pretty much any criteria. For example, you can limit requests based on client IP address (so Twitterbot doesn't overload your site), the requested domain (so one website doesn't affect the performance of other sites in your account), whether the request is coming from a local or remote client (useful for handling "circular requests"), or pretty much anything else you might want. As a general-purpose process tool, Q is also useful for solving concurrency race conditions, making sure that only a single instance of a program is running at once, and other common scripting requirements.
Q is developed by Christopher Sebastian and Ryan Sanden. Feel free to ask us questions and send feedback. Note: Q is not officially supported by WebFaction, so please do not submit questions to the WebFaction Support Team. Send them to us instead.
Installation
Installation consists of two pieces: downloading a Q binary, and then referencing the binary from your website's .htaccess file.
-
In all of the below instructions, make the following name substitutions:
- APP = Your Application Name, defined in the WebFaction Control Panel, and corresponding to a folder under ~/webapps/.
- Q.cgi = The actual filename that you download from the table below (probably php54_normal.cgi).
Download an appropriate binary, give it a proper set of permissions, and place it at ~/webapps/APP/. You can do this from the command line like this:
cd ~/webapps/APP/ curl -O http://q.likebike.org/bin/centos6/Q.cgi ### Replace this URL with the appropriate one from the table below. chmod 755 Q.cgi
If your account is on a CentOS 6 server (Web300 or higher):
CentOS 6 PHP 5.2 PHP 5.3 PHP 5.4 CGI (Advanced) Normal Account
(If you have a 256MB/512MB plan)php52_normal.cgi php53_normal.cgi php54_normal.cgi Q Large Account
(If you have a 1GB/2GB/4GB plan)php52_large.cgi php53_large.cgi php54_large.cgi If your account is on a CentOS 5 server (Web299 or lower):
CentOS 5 PHP 5.2 PHP 5.3 PHP 5.4 CGI (Advanced) Normal Account
(If you have a 256MB/512MB plan)php52_normal.cgi php53_normal.cgi php54_normal.cgi Q Large Account
(If you have a 1GB/2GB/4GB plan)php52_large.cgi php53_large.cgi php54_large.cgi Here is a link to the latest source code. You can also browse the distribution mirror.
-
Edit your ~/webapps/APP/.htaccess file and add these lines to the top of the file. Remember to replace both instances of Q.cgi with the actual file you downloaded:
<FilesMatch ^Q.cgi$> SetHandler cgi-script </FilesMatch> Action php-q /Q.cgi <FilesMatch \.(?i:php)$> SetHandler php-q </FilesMatch>That's it! Once you save these changes, your site will be running from Q!
Frequently Asked Questions
If you have a question that is not addressed here, please send it to Christopher.
-
Which PHP version am I running?
Create an info.php file in your web app with the following contents:
<?php phpinfo(); ?>
When you visit that page, the PHP version will be printed at the top of the screen. Remember to delete the info.php file when you are done with it so other people can't see your settings!
-
What is the difference between the "normal" and "large" binaries?
They are configured to run different numbers of concurrent processes. The "normal" settings are appropriate for basic WebFaction accounts, and the "large" settings are better for accounts with more RAM.
-
I am using Q, but I forgot which one I downloaded. How can I see which Q settings I am currently using?
Run your Q binary with the HELP=1 environment defined, as shown below. The resulting help message will list your settings.
HELP=1 ./Q.cgi
Performance & Reliability
- Q is implemented in C, and depends only on the C standard library. Because of this, it is easy to build on any Linux system.
- Q uses Linux Record Locking for inter-process communication. This method is very fast and it does not involve any filesystem activity, other than the one-time creation of a lockfile.
- Since Linux Record Locking is managed by the Linux Kernel, the queue is guaranteed to never get "stuck", even if processes crash or are sent un-handleable signals like SIGSTOP and SIGKILL.
- On a 32-bit system, a Q process uses around 430kB of RSS memory (most of which is from the standard C library, and therefore shared). On a 64-bit system, a Q process uses around 540kB.
- Q uses intelligent binary search algorithms, along with other optimizations, to achieve excellent scalability and low resource usage. It is able to manage more processes than the Linux Kernel is currently able to handle. (In other words, Q will never be the performance bottleneck.)
How Q Works
Example #1: Running N Processes at a Time
Pretend that you have written a program named SWAAG, which converts images to ASCII art. The generation of this ASCII art is very CPU-intensive, but not demanding in terms of RAM or Disk I/O. SWAAG is single-threaded and synchronous, so it only uses one CPU core when it runs. Also pretend that your computer has 4 CPU cores, but you only want to use 3 of them for ASCII art conversions. (You need the other core for productivity YouTube.) You have a directory with 100 images that you need to convert, named image00.png to image99.png.
Q makes these kinds of tasks easy. You would just need to type this bash command:
for image in image*.png; do
COMMAND=swaag CONCURRENCY=3 ./Q "$image" &
done
Here are some graphical views of the execution (click to enlarge):
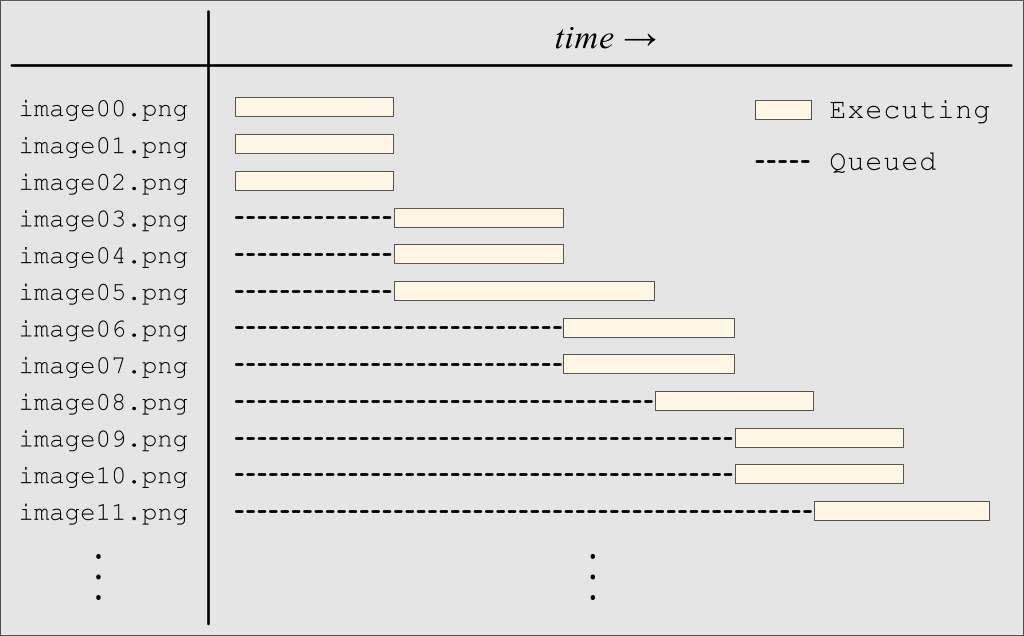
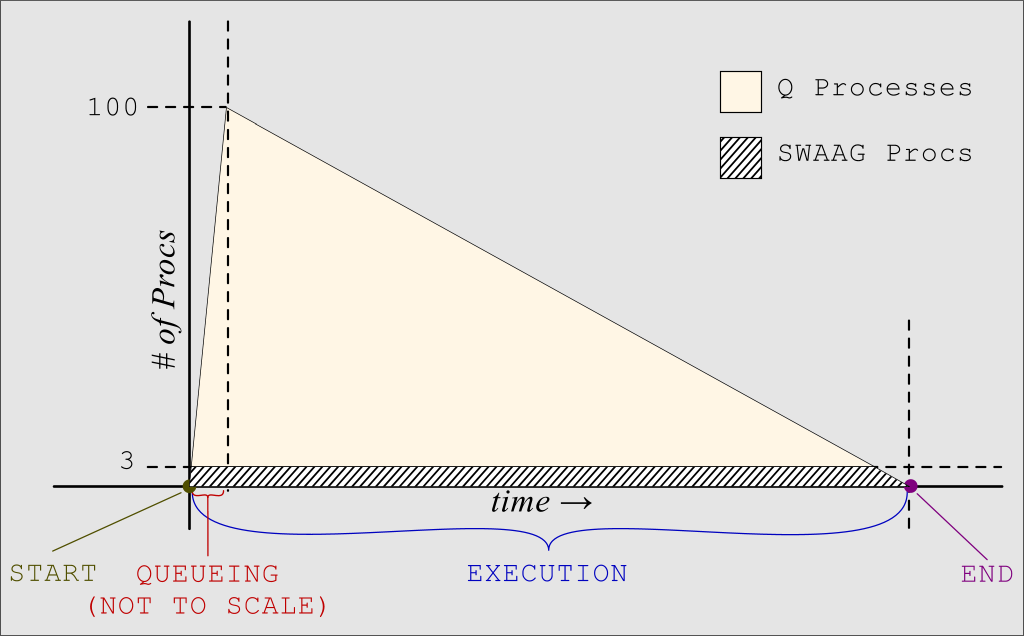
There are several phases of execution, as shown in the diagrams above:
The START Phase:
This is the point right before you type the above command and press ENTER. At this point, no Q or SWAAG processes are running.
The QUEUEING Phase:
This phase represents the fraction of a second when the above bash loop is running. The bash loop quickly launches 100 Q processes in the background. At the end of this phase, you will momentarily have approximately 100 Q processes running:
$ ps -o pid,rss,%cpu,cmd -p $(pgrep -u $USER '^Q$|^swaag$') PID RSS %CPU CMD 1000 540 0.0 Q 1001 540 0.0 Q 1002 540 0.0 Q 1003 540 0.0 Q 1004 540 0.0 Q 1005 540 0.0 Q ... ... 1097 540 0.0 Q 1098 540 0.0 Q 1099 540 0.0 Q
Immediately, 3 of the Q processes will convert themselves into SWAAG processes (because we specified CONCURRENCY=3). Note that the original process ID (PID) numbers will be retained, since exec is used (this is a critical feature for many advanced cases). At that point, there would be 3 SWAAG processes and 97 Q processes. The process listing would look something like this:
$ ps -o pid,rss,%cpu,cmd -p $(pgrep -u $USER '^Q$|^swaag$') PID RSS %CPU CMD 1000 58000 99.9 swaag 1001 55000 99.9 swaag 1002 59000 99.9 swaag 1003 540 0.0 Q 1004 540 0.0 Q 1005 540 0.0 Q ... ... 1097 540 0.0 Q 1098 540 0.0 Q 1099 540 0.0 Q
The EXECUTION Phase:
After a SWAAG process completes, the next Q in line will convert itself into a new SWAAG and start running. The process listing would look something like this (notice that PID 1000 is no longer in the list, and PID 1003 has taken its place):
$ ps -o pid,rss,%cpu,cmd -p $(pgrep -u $USER '^Q$|^swaag$') PID RSS %CPU CMD 1001 55000 99.9 swaag 1002 59000 99.9 swaag 1003 57000 99.9 swaag 1004 540 0.0 Q 1005 540 0.0 Q 1006 540 0.0 Q ... ... 1097 540 0.0 Q 1098 540 0.0 Q 1099 540 0.0 Q
This pattern continues until all Q processes have waited their turn and then converted themselves into SWAAG processes.
The END Phase:
This phase represents the point in time when all Q processes have been converted, and have finished running.
Example #2: Running One Process at a Time
Pretend that you have a production PostgreSQL database that your business depends on. Data changes often, so you need to take hourly backups. Most of the time, those backups complete within the hour. However, if the database server is particularly busy, it could take longer. You can't really know in advance the maximum length of time that any one export could take, and you don't want more than one of these database export processes running at once. If it happens that a previous export process is still running when the next starts, the new one should just exit immediately without running. You never want these processes to overlap.
Q can also be used for this type of application. You would use an hourly cron job like this:
0 * * * * CONCURRENCY=1 MAX_Q=0 COMMAND=/usr/bin/pg_dump ~/bin/Q -U mypguser -f ~/pg_backups/mydb.sql mydb
This will run Q each hour, instructing Q to run the command "/usr/bin/pg_dump -U mypguser -f /home/myuser/pg_backups/mydb.sql mydb" with CONCURRENCY=1 and MAX_Q=0. This means that the pg_dump commands will execute one at a time (CONCURRENCY=1), and that processes never queue up, but instead exit immediately without running (MAX_Q=0).
To understand how this works, it's helpful to visualize the process array. This visualization will assume CONCURRENCY=3 and MAX_Q=6 for increased demonstrative clarity:
|
Structure Overview
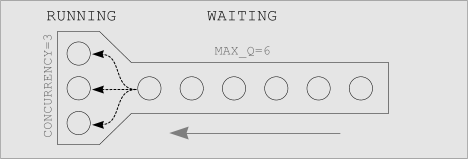
|
The process array has two primary regions; the RUNNING region and the WAITING region. We are assuming CONCURRENCY=3 and MAX_Q=6, so the process array has 3 RUNNING slots and 6 WAITING slots. Processes in the WAITING region are Q processes waiting their turn in line. Processes in the RUNNING region are no longer Q processes, but have already been converted into the target COMMAND. |
|
A Process is added to the Queue
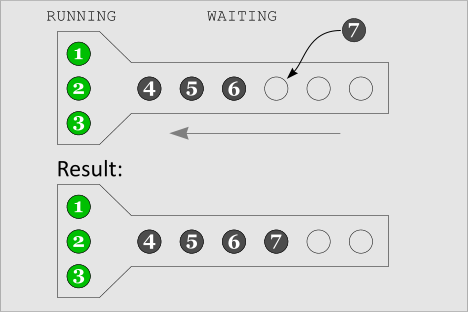
|
In this image, we've initially populated the process array with some processes. The first 3 processes (labeled 1, 2, and 3) immediately went into the RUNNING region, since the array was initially empty. The next 3 processes (labeled 4, 5, and 6) went into the WAITING region, since the RUNNING region was already full. This image illustrates the addition of another process, labeled 7. As expected, it inserts itself at the end of the process array. The result is that there are now 7 total processes in the process array, with three RUNNING and four WAITING. |
|
A RUNNING process finishes, and
the next WAITING process takes its place 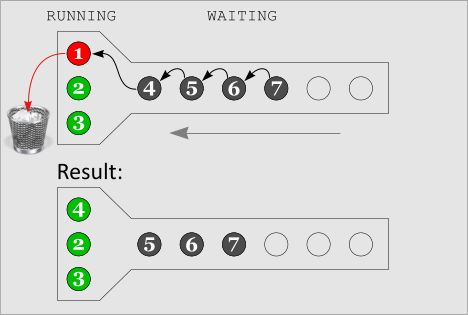
|
This image illustrates the completion of one of the RUNNING processes, in this case the process labeled 1. The next-in-line process in the WAITING region moves to take its place, in this case the process labeled 4. All processes move forward. The result is that Q process 4 has now been converted into its associated COMMAND. Processes 2 and 3 are still running (they haven't completed yet), and three process (5, 6, and 7) are left WAITING. |
|
A process is discarded when Queue is full
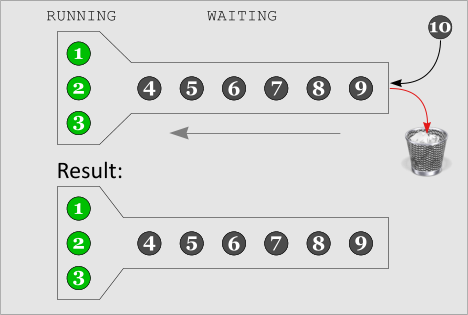
|
This image illustrates that when the queue is completely full, any new Q processes exit immediately without ever running their COMMAND. The result is that no more processes than MAX_Q are ever queued up WAITING. |
The Q process array has two regions, the RUNNING region and the WAITING region. When a new Q process is launched, it inserts itself at the end of the array.
- If it lands in one of the first few spots, in the RUNNING region, then Q immediately executes the command.
- If it lands in the WAITING region, then Q will wait in line until it reaches the RUNNING region before executing its associated command.
- If it lands after the end of the queue, past the WAITING region, then all slots are already full. Q exits immediately without running the command at all.
As soon as any one of the processes in the RUNNING region finishes, all of the Q processes waiting in line behind it move forward. This means that the next-in-line WAITING Q process will move into a RUNNING slot, and then Q will execute it. It also means that there is one more empty slot in the WAITING region, which a new Q process could come and fill.
One important feature of this approach is that there is no "master" Q process which runs as a daemon and regulates all of the other processes. All of the Q processes are independent and you do not need to manage a "Q server" which handles the scheduling. Each individual Q process follows the following logic:
- If (position <= CONCURRENCY):
exec associated command (which completes this Q process) - If (CONCURRENCY < position <= (CONCURRENCY + MAX_Q)):
sleep awhile and then check position again. - If (position > (CONCURRENCY + MAX_Q)):
exit(-17) without running the command.
Compile-time Options:
As demonstrated, Q uses environment variables for configuration. These settings can also be defined at compile-time. Furthermore, if you define a setting this way, it cannot be overridden with an environment variable. This is by design - it allows administrators to hard-code values and be sure that they don't change.
To hard-code a value, define them as macros at compile time via the CPPFLAGS environment variable. For example, the following will hard-code CONCURRENCY=1 and MAX_Q=0, and rename the resulting file to run_single, because that's what it does:
CPPFLAGS="-DCONCURRENCY=1 -DMAX_Q=0" make mv ./Q ~/bin/run_single
At this point, the "run_single" binary is Q with some hard-coded values. You would run the database cron using this new binary as follows:
0 * * * * COMMAND=/usr/bin/pg_dump ~/bin/run_single -U mypguser -f ~/pg_backups/mydb.sql mydb
You now have a convenient portable binary application that runs a single instance of a program at once.
Any of the following five variables can be defined at compile-time. Each of these answers a different question:
- COMMAND -- Which program should run?
- CONCURRENCY -- How many instances can be running at once?
- MAX_Q -- How many instances can wait in line if all running slots are full?
- Q_FILE -- How do we define which queue a process is put into?
- AUTO_CREATE_DIRS -- Should parent directories of the Q_FILE be created automatically?
The variables Q_FILE and AUTO_CREATE_DIRS will be explained in more detail shortly.
Example #3: Running N processes at a time, allowing only M to be queued at once
Imagine that you are running a PHP 5.4 website in CGI mode. You want to handle 3 concurrent requests, but you also can't afford to queue unlimited numbers of requests because Apache processes are very heavy. You would like to limit the queue length to 20.
For this situation, it makes a lot of sense to create a compiled drop-in replacement for the PHP binary:
CPPFLAGS="-DCONCURRENCY=3 -DMAX_Q=20 -DCOMMAND=/home/cgi-php/php54.cgi" make mv ./Q ~/webapps/myapp/php54.cgi
You can then place the binary in your webroot as shown above (~/webapps/myapp/php54.cgi), and you can add these directives to your .htaccess file:
<FilesMatch ^php54.cgi$>
SetHandler cgi-script
</FilesMatch>
Action php-q /php54.cgi
<FilesMatch \.(?i:php)$>
SetHandler php-q
</FilesMatch>
Then, when a PHP request comes in for this application, a Q process gets started instead of a normal php54.cgi process. The new Q process checks its position in the queue as described in the previous example. Once it's ready, it exec's the real PHP binary.
Under normal circumstances, the new Q process doesn't need to wait and just executes immediately. During a traffic spike, however, the Q processes queue up. It's much better to queue up several Q processes (540kB each) than many php54.cgi processes (48MB each). Furthermore, they will execute in FIFO order and will not overlap to the point of slowing each other down. As a result, this prevents traffic spikes from using large amounts of RAM and can even improve performance as well.
In addition to the above, Q also provides powerful queuing flexibility. Instead of having a single queue for all of your php54.cgi processes (the default), you can specify different queues using the Q_FILE setting. To understand how this works, revisit the above example in more detail. When a PHP request comes in for a particular domain, a new Q process gets started instead of a normal php54.cgi process. The new Q process checks its position in its associated Q_FILE, and either executes immediately, waits in line, or else exits immediately depending on how many other Q processes are waiting in that same Q_FILE.
By putting different domains into different queues, you can separate traffic. Imagine that you are a developer and hosting clients' websites, each of which should receive comparable performance. If one of those sites gets significantly more traffic than the others, that site will bog down the other sites. Applying Q could solve this problem nicely by placing each website into its own separate queue with, perhaps, CONCURRENCY=2 and MAX_Q=20. The relatively busy site will experience longer load times during traffic spikes (requests having to wait for their turn to execute) but other clients' sites would remain fast as long as their own RUNNING regions remained unsaturated..
Accomplishing such separate queues is straightforward because environment variables can be used in the Q_FILE path. To do this, simply compile in a Q_FILE which uses the domain ("$SERVER_NAME" -- a standard CGI environment variable) in its filename. This means multiple Q_FILEs (one for each domain) will exist, and requests for a particular domain will queue into its associated Q_FILE:
CPPFLAGS="-DQ_FILE='~/.tmp/Q/cgi_$SERVER_NAME.Q' -DCONCURRENCY=3 -DMAX_Q=20 -DCOMMAND=/home/cgi-php/php54.cgi" make mv ./Q ~/webapps/myapp/php54.cgi
That's it. The $SERVER_NAME environment variable will be evaluated at runtime (it's set by apache), and requests will go into the appropriate Q_FILE. If the file doesn't exist, it will be created on first use. If the AUTO_CREATE_DIRS setting is not set to 0, then any necessary parent directories for the Q_FILE will be created as needed. Finally, if for some reason the Q_FILE can't be created, Q will defer to always running the process immediately. This means you'll lose queuing functionality until the problem is fixed, but it won't break your websites.
Manpage
Here is Q's standard help text, for your easy reference:
Q Version 1.1.1 -- a FIFO worker queue, capable of running multiple workers at once.
Typical usage: COMMAND=/usr/bin/rsync ./Q [args...]
The args get passed directly to COMMAND.
Environment Variables:
COMMAND=path -- Required. The path to the target executable. Should usually be an absolute path.
Q_FILE=path -- The path to the Q queue state file. More info below.
CONCURRENCY=num -- Controls the number of workers to run at once. Default is 1.
MAX_Q=num -- Controls the maximum queue size (# waiting to run). Default is -1 (unlimited).
AUTO_CREATE_DIRS -- Set to 0 to prevent the Q_FILE parent directories from being auto-created.
VERBOSE -- Set to 1 to display verbose information.
HELP -- Set to 1 to display this help message and then exit.
By default, Q_FILE is set to ~/.tmp/Q/cmd_$(basename $COMMAND).Q, but you can change this.
You can use the tilde (~) and environment variables ($VAR) in the Q_FILE.
This enables you to achieve some interesting queuing structures:
Q_FILE=example.Q # A relative path can queue jobs based on $PWD.
Q_FILE=/tmp/shared.Q # A system-wide queue. (You would need to chmod 666 it.)
Q_FILE='~/myjobs.Q' # Use a per-account queue.
Q_FILE='~/.tmp/Q/cgi_$SERVER_NAME.Q' # Assuming this is for CGI processes, use a per-domain queue.